Document Statistics
The Document Statistics page provides detailed information about how a document was processed.
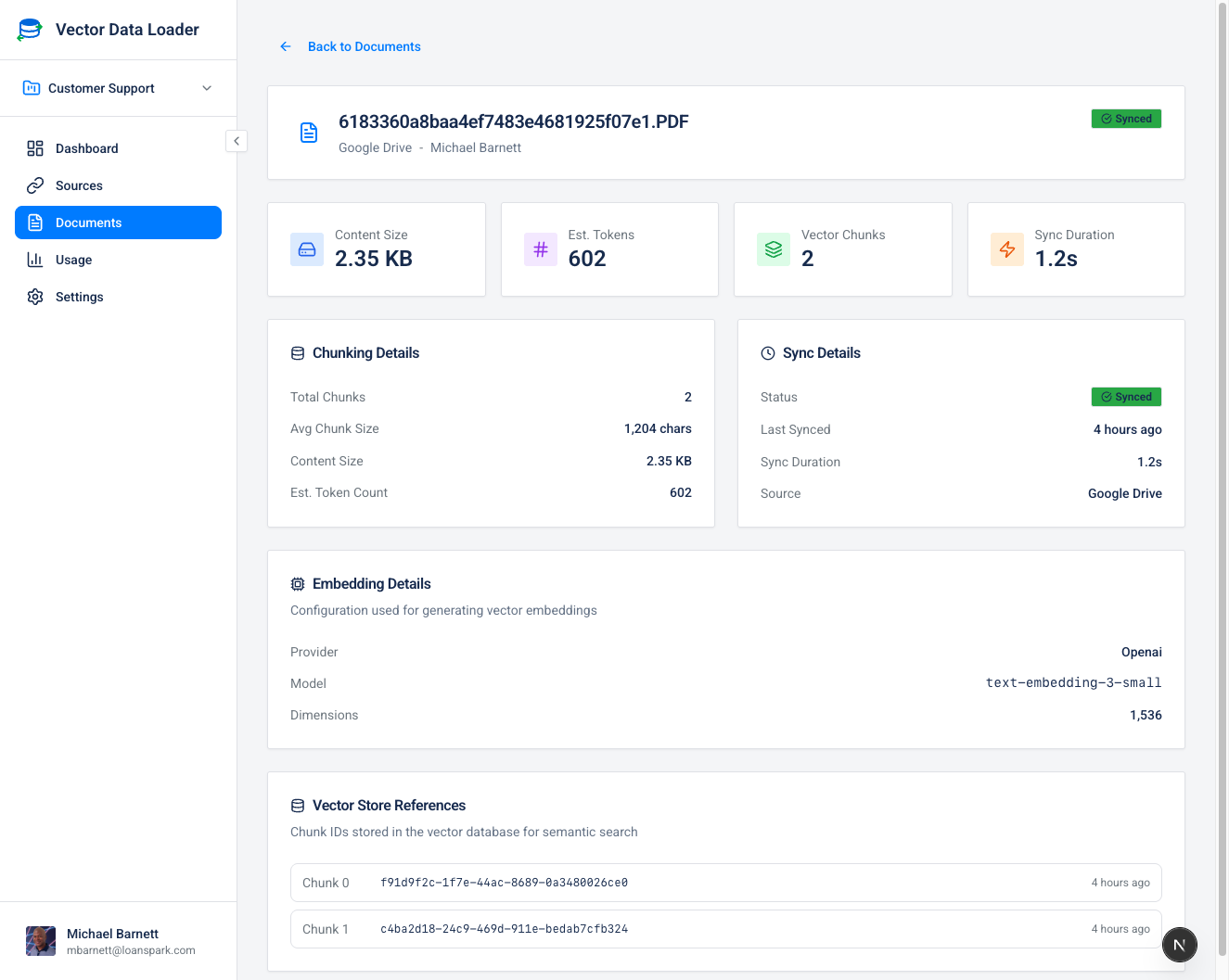
Overview Section
| Metric | Description |
|---|---|
| Content Size | Size of the extracted text content in bytes |
| Estimated Tokens | Approximate token count for LLM context planning |
| Vector Chunks | Number of chunks created in the vector store |
| Sync Duration | Time taken for the last sync operation |
Chunking Details
Shows how the document was split:
| Field | Description |
|---|---|
| Splitter Type | Algorithm used for chunking: Header-Aware (HTML), Header-Aware (Markdown), or Recursive Text |
| Contextual Retrieval | Whether enhanced context was generated for each chunk. Shows "Enhanced" with LLM cost if used, or "Standard" if not |
| Total Chunks | Number of chunks created from the document |
| Average Chunk Size | Mean character count per chunk |
| Content Size | Total size of extracted text |
| Est. Token Count | Approximate tokens for the document |
Splitter Types Explained
| Type | Description | Best For |
|---|---|---|
| Header-Aware (HTML) | Splits at HTML header tags (h1, h2, etc.) preserving hierarchy | Web pages, Confluence, HTML docs |
| Header-Aware (Markdown) | Splits at Markdown headers (#, ##, etc.) | Markdown files, GitHub READMEs |
| Recursive Text | Splits at natural boundaries (paragraphs, sentences) | PDFs, plain text, unstructured content |
Contextual Retrieval Status
When a document is synced with Enhanced with Contextual Retrieval, the stats page shows:
- Enhanced label with a sparkle icon
- LLM cost in parentheses (e.g., $0.002)
Documents synced with standard mode show Standard in muted text.
Embedding Details
Information about the embedding process:
- Model Used: Which embedding model processed this document
- Dimensions: Vector dimensionality (e.g., 1536 for OpenAI)
Vector Store References
Shows where chunks are stored:
- Provider: Active vector store (Supabase, Pinecone, etc.)
- Collection/Table: Specific storage location